
깜푸의 패스트캠퍼스 데이터분석 부트캠프 8주차 학습일지

아래의 예시를 위해 다음과 같은 테이블을 미리 생성
SELECT & FROM 구문
: 불러올 데이터를 지정해주는 키워드
SELECT [컬럼명] FROM [테이블명]
º SELECT ~ FROM 구문 앞에 사용할 데이터베이스명을 USE [데이터베이스명]으로 지정하지 않는다면
FROM [데이터베이스명].[테이블명] 으로 테이블이 담긴 데이터베이스명을 작성해야함
(아래의 쿼리문은 USE [데이터베이스명] 으로 데이터베이스를 앞에서 지정해주었다는 기준으로 작성)
ex) 아이스크림 테이블에서 전체 컬럼을 가져오기
SELECT * FROM icecream ;
( * 은 all 을 의미 )
ex) 아이스크림 테이블에서 name 컬럼만 가져오기
ºSELECT 절에 집계 함수를 사용할 수 있다
(집계 함수는 SELECT, HAVING 절에서 사용 가능, WHERE 절에는 사용 X)
ex) 전체 행에 대한 아이스크림 총 가격, 평균 가격, 최대 가격, 최소 가격
LIMIT 절
: 결과값 테이블의 행 개수 지정하는 키워드
ex) 아이스크림 테이블에서 전체 컬럼 중에서 5개의 행만 가져오기
WHERE 조건절
: 가져올 데이터 값에 조건을 지정해주는 키워드
: WHERE 절에 원하는 필터를 지정한다고 생각
SELECT [컬럼명]
FROM [테이블명]
WHERE [조건식]
ex) 막대 타입의 아이스크림 이름만 가져오기
º 연산자를 이용하여 여러 개의 조건을 지정할 수 있다
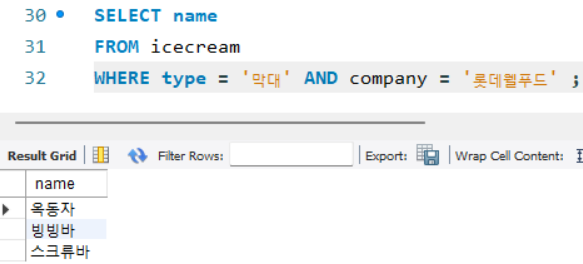
ex) 막대 타입이면서 제조사가 롯데웰푸드인 아이스크림의 이름 가져오기
º 와일드카드를 이용하여 문자열 조건을 지정할 수 있다
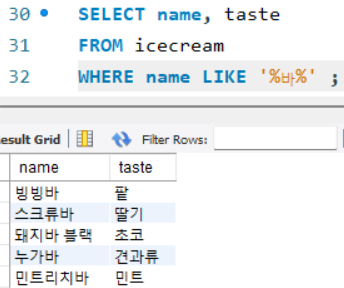
ex) 이름에 '바'가 들어가는 아이스크림의 이름과 맛 컬럼 가져오기
WHERE [컬럼명] LIKE '와일드카드문'
GROUP BY 그룹 생성
: 원하는 그룹별로 데이터 값을 묶어주는 키워드
SELECT [컬럼명]
FROM [테이블명]
GROUP BY [컬럼명]
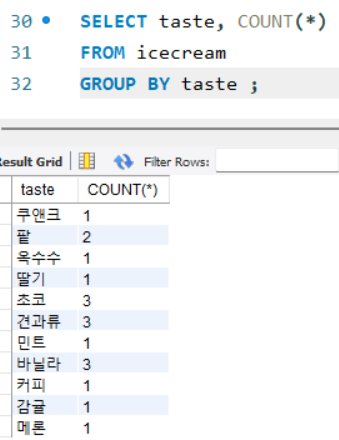
ex) 맛별로 아이스크림의 개수 세기
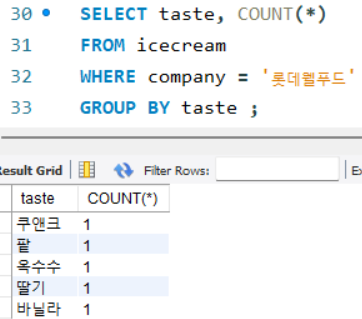
ex) 제조사가 롯데웰푸드인 아이스크림을 맛별로 개수 세기
HAVING 조건절
: 그룹의 조건을 지정해주는 키워드
SELECT [컬럼명]
FROM [테이블명]
GROUP BY [컬럼명]
HAVING [조건식]
ex) 맛별로 아이스크림의 개수 세기 (단, 개수가 2개 이상인 맛만 출력)
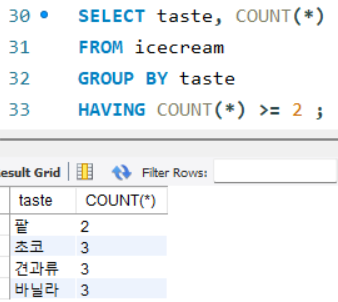
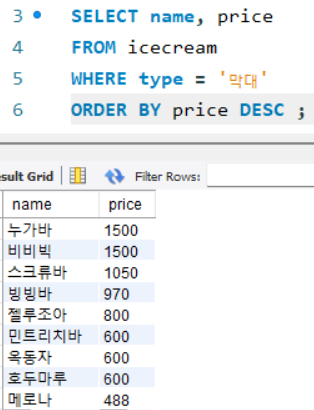
ORDER BY 절
: 행을 정렬해주는 키워드
ex) 막대 타입의 아이스크림을 가격 순으로 내림차순 정렬하기
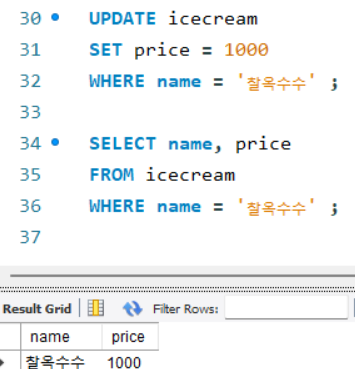
데이터 수정
: 테이블에 저장된 데이터를 수정하는 키워드 UPDATE
UPDATE [테이블명]
SET [수정하고싶은 컬럼명] = '수정하고싶은 값' - 컬럼으로 여러개의 수정 사항을 연결할 수 있음
WHERE [특정 컬럼] = '값' - 특정 컬럼은 PRIMARY KEY로 지정된 컬럼만 가능
ex) 찰옥수수의 가격 변경하기 (기존 990 → 변경 1000)
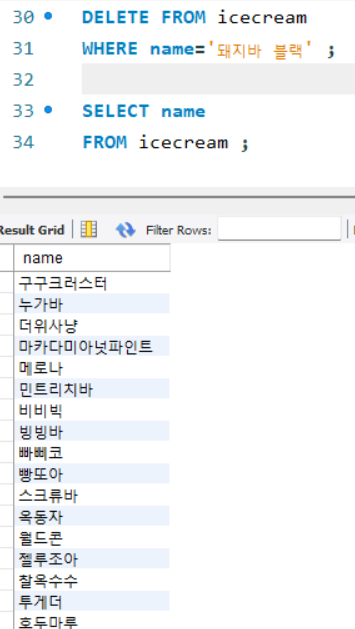
데이터 삭제
: 테이블에 저장된 데이터를 삭제하는 키워드 DELETE
ex) 돼지바 블랙에 대한 정보 지우기
PRIMARY KEY / FOREIGN KEY 지정하기
: 테이블 각 컬럼에 PRIMARY KEY 기본키, FOREIGN KEY 외래키를 지정할 수 있다
: 테이블을 생성할 때, KEY를 지정할 수 있고
: 이미 테이블이 생성되었다면, ALTER TABLE 키워드를 사용하여 KEY를 지정할 수 있다
º 테이블을 생성할 때 기본키 지정하는 법

(NOT NULL 키워드와 함께 사용 가능)
(다른 컬럼들도 NOT NULL 키워드 사용할 수 있으며, 한번에 여러개의 기본키를 설정할 수 있다)
º 이미 생성된 테이블에 기본키를 지정하는 법

º 외래키 지정하는 법

º 외래키가 지정되어있는 테이블에 데이터를 추가할 때, 참고되어있는 테이블에 없는 값이 입력되면 오류 발생
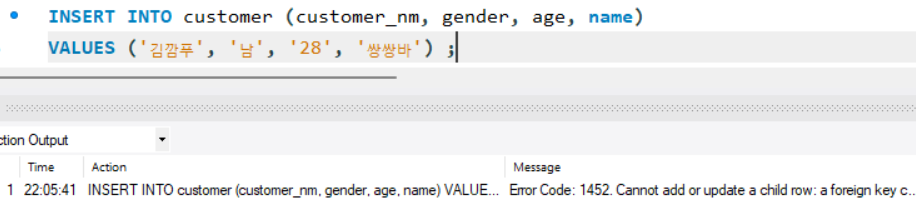
name 컬럼이 외래키로 참조하고있는 icecream 테이블의 name 컬럼에 '쌍쌍바'라는 항목이 없으므로 오류 발생
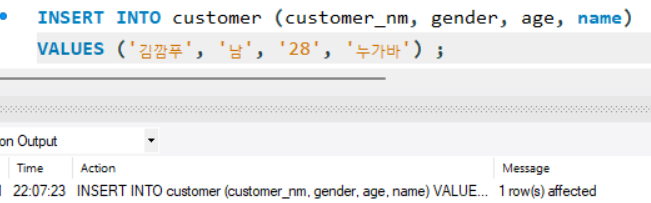
그러나 icecream 테이블 name 컬럼에 있는 항목인 '누가바'를 입력하면 실행됨
(데이터 무결성을 위한 조건)
UNION
: 두 개 이상의 SELECT 문의 결과를 결합하는 키워드
SELECT [컬럼명]
FROM [테이블명 1]
UNION
SELECT [컬럼명]
FROM [테이블명 2]
- UNION : 중복된 값 제거한 전체 값
- UNION ALL : 중복된 값 포함한 전체 값
- INTERSECT : 교집합
- EXCEPT : 차집합
조인 활용하기
: 두 개 이상의 테이블로부터 필요한 데이터를 연결해 하나의 포괄적인 구조로 결합
: INNER JOIN (교집합) / OUTER JOIN (합집합)
º INNER JOIN은 두 테이블이 일치하는 값만 출력
SELECT * FROM [테이블명 1]
INNER JOIN [테이블명 2] ON [테이블명 1].[컬럼명] = [테이블명 2].[컬럼명]
º OUTER JOIN은 두 테이블의 모든 값을 출력
SELECT * FROM [테이블명 1]
OUTER JOIN [테이블명 2] ON [테이블명 1].[컬럼명] = [테이블명 2].[컬럼명]
서브쿼리문 작성하기
: 키워드 안에 쿼리문을 삽입하는 것
: 출력 결과 값에 여러 테이블의 컬럼이 필요한 경우 사용
º SELECT 절의 서브쿼리문
: 다른 테이블에서 가져오고싶은 컬럼을 서브쿼리문으로 가져올 수 있다
SELECT (SELECT [컬럼명], · · · FROM [테이블명 1] ~~~)
FROM [테이블명 2]
·
·
º FROM 절의 서브쿼리문
: 다른 테이블에서 가져오고싶은 데이터를 테이블 형태로 가져올 수 있다
: FROM 절의 서브쿼리문은 반드시 AS 를 사용하여 별명을 붙여줘야한다
: (foo 로 대체 가능)
SELECT [컬럼명], · · ·
FROM (SELECT ~ FROM ~ ) AS [별명]
·
·
º WHERE 절의 서브쿼리문
: 다른 테이블에서 조건을 연결하여 본 쿼리문의 조건을 매칭할 수 있다
SELECT [컬럼명], · · ·
FROM [테이블명]
WHERE [컬럼명] [비교연산자] (SELECT ~ FROM ~)
인덱스 설정하기
: DB에서 테이블에 대한 동작의 속도를 높여주는 자료 구조
- 클러스터형 인덱스
: 데이터를 실제로 재정렬하여 저장
: PRIMARY KEY로 정의한 컬럼이 있을 경우 자동 생성됨
: 한 테이블당 한 개의 클러스터형 인덱스만 가질 수 있음
- 보조 인덱스
: 데이터는 그대로 유지되고, 인덱스가 생성
: 각 데이터의 위치만 빠르게 찾을 수 있음
: 필요한 디스크 공간이 적음 (키-필드만 갖고있기때문)
º 인덱스 확인
SHOW INDEX FROM [테이블명]
º 인덱스 생성
: 생성할 인덱스의 기준이 될 컬럼 지정, 생성할 인덱스의 이름 지정
CREATE INDEX [인덱스명] ON [테이블명] (컬럼명)
º 인덱스 추가
ALTER TABLE [테이블명] ADD INDEX [인덱스명] (컬럼명)
문자열 함수
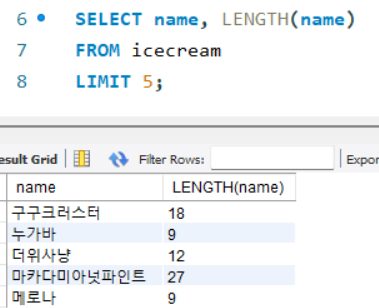
- LENGTH() : 문자열의 길이 반환
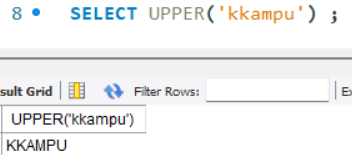
- UPPER() : 문자열을 대문자로 변환
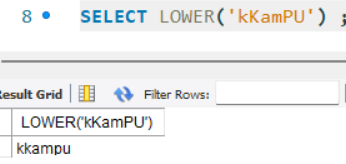
- LOWER() : 문자열을 소문자로 변환
: 대소문자가 섞여있는 문자열도 가능
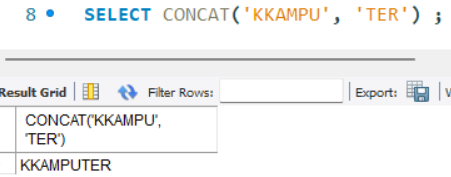
- CONCAT(문자열1, 문자열2, ... ) : 두 개 이상의 문자열을 하나로 연결
: 테이블의 컬럼으로도 적용 가능
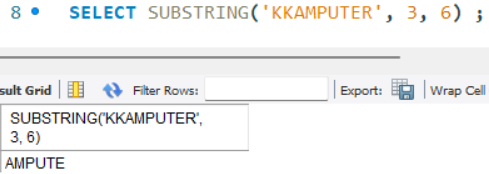
- SUBSTRING(문자열, 문자열 추출을 시작할 지점, 길이)
: 문자열에서 일부를 추출
날짜/시간 함수
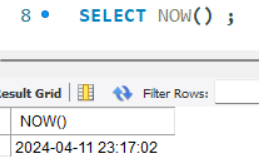
- NOW() : 현재 날짜와 시간 반환
- CURDATE() : 현재 날짜 반환
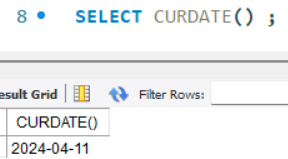
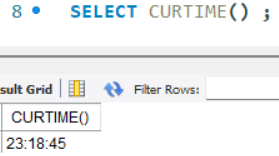
- CURTIME() : 현재 시간 반환
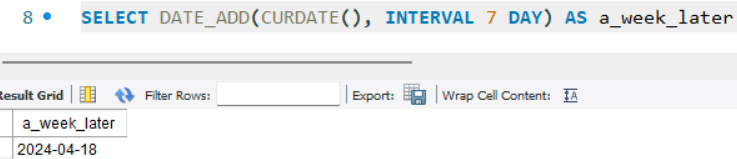
- DATE_ADD(날짜, INTERVAL 숫자) : 날짜에 숫자만큼 더한 날짜 반환

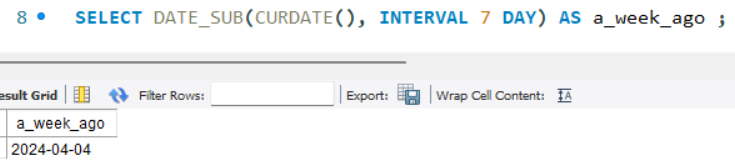
- DATE_SUB(날짜, INTERVAL 숫자) : 날짜에 숫자만큼 뺀 날짜 반환

- YEAR() : 날짜의 년도 반환
- MONTH() : 날짜의 월 반환
- DAY() : 날짜의 일 반환
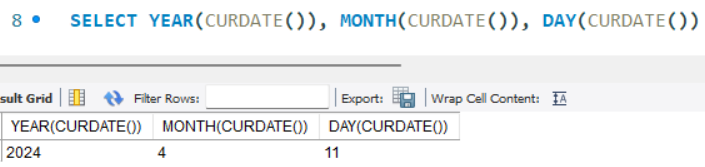
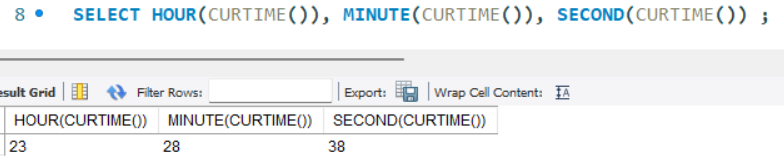
- HOUR() : 시간의 시 반환
- MINUTE() : 시간의 분 반환
- SECOND() : 시간의 초 반환
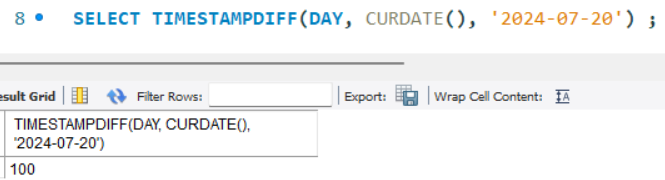
- TIMESTAMPDIFF(DAY, 시작일, 종료일) : 시작일과 종료일 사이의 일수 차이 반환
- TIMESTAMPDIFF(HOUR, 시작일, 종료일) : 시작일과 종료일 사이의 시간 차이 반환
- DATE_FORMAT() : 날짜 혹은 시간을 특정 형식으로 포매팅
| %Y : 4자리 연도 | %y : 2자리 연도 | %M : 월 이름 (April, May, ...) | %m : 2자리 월 (04,05, ...) |
| %D : 일 (1st, 2nd, ...) | %d : 2자리 일 (01, 02, ...) | %H : 24시간 형식 시간 | %h : 12시간 형식 시간 |
| %i : 2자리 분 | %s : 2자리 초 |
숫자 함수
- ABS() : 숫자의 절댓값 반환
- CEIL() : 숫자를 반올림하여 정수로 반환
- FLOOR() : 숫자를 내림하여 정수로 반환
- ROUND() : 숫자를 특정 자리수에서 반올림
- SQRT() : 숫자의 제곱근 반환
TRANSACTION
: DB의 데이터값을 변경할 때, TRANSACTION을 실행한 뒤 변경했던 값들을 복구하고 싶을 때 ROLLBACK으로 되돌릴 수 있다
: TRANSACTION 실행 뒤, COMMIT을 사용해주면 변경했던 값들이 고정되어 ROLLBACK 불가능
ex 1)
데이터 변경 전의 데이터 값으로 돌아간다 (트랜젝션 이전 데이터값)
# 트랜잭션 실행
START TRANSACTION ;
#데이터 변경
UPDATE ~
SET ~
#데이터 복구
ROLLBACK ;
ex 2)
데이터 변경 후의 데이터 값으로 고정됨. 이후에 ROLLBACK 사용해도 데이터 복구되지않음
트랜잭션의 실행이 종료된다고 생각
# 트랜잭션 실행
START TRANSACTION ;
#데이터 변경
UPDATE ~
SET ~
#데이터 고정
COMMIT ;
ex 3)
변경된 데이터가 ROLLBACK으로 복구된 뒤, COMMIT으로 값이 고정됨
트랜잭션 실행 이전의 데이터 값으로 변경
# 트랜잭션 실행
START TRANSACTION ;
#데이터 변경
UPDATE ~
SET ~
#데이터 복구
ROLLBACK ;
#데이터 고정
COMMIT ;
'DATA | IT > 패스트캠퍼스 BDA 13기' 카테고리의 다른 글
| [패스트캠퍼스 데이터 분석 부트캠프] 11주차_Tableau (0) | 2024.05.03 |
|---|---|
| [패스트캠퍼스 데이터 분석 부트캠프] 9주차_SQL 문법 (윈도우 함수) (2) | 2024.04.19 |
| [패스트캠퍼스 데이터 분석 부트캠프] 7주차_SQL 기초 문법 (0) | 2024.04.08 |
| [패스트캠퍼스 데이터 분석 부트캠프] 4주차_파이썬 제어문과 반복문(If문, While문, For문) (0) | 2024.04.08 |
| [패스트캠퍼스 데이터 분석 부트캠프] 3주차_파이썬Python 기초 문법 배우기- 자료형, 리스트, 튜플, 인덱싱 (1) | 2024.04.08 |



