
깜푸의 패스트캠퍼스 데이터분석 부트캠프 3주차 학습일지
렛츠 고
CH00. 프로그래밍의 이해
<진법>
: 0부터 n개의 숫자를 사용하여 수를 표현하는 방법
- 2진법(0b) = 0과 1 두개의 숫자를 사용, 컴퓨터에 유용
- 10진법 (0o)= 0 ~ 9까지의 10개의 숫자를 사용, 일상적으로 사용됨
- 16진법 (0x or 0X)= 0 ~ 9 까지 10개의 숫자와 A ~ F 까지의 6개의 문자 사용
* 진법 변환
2진수 → 16진수 로 변환할 때, 2진수를 뒤에서부터 4자리씩 끊고, 끊은 부분을 16진수로 변환
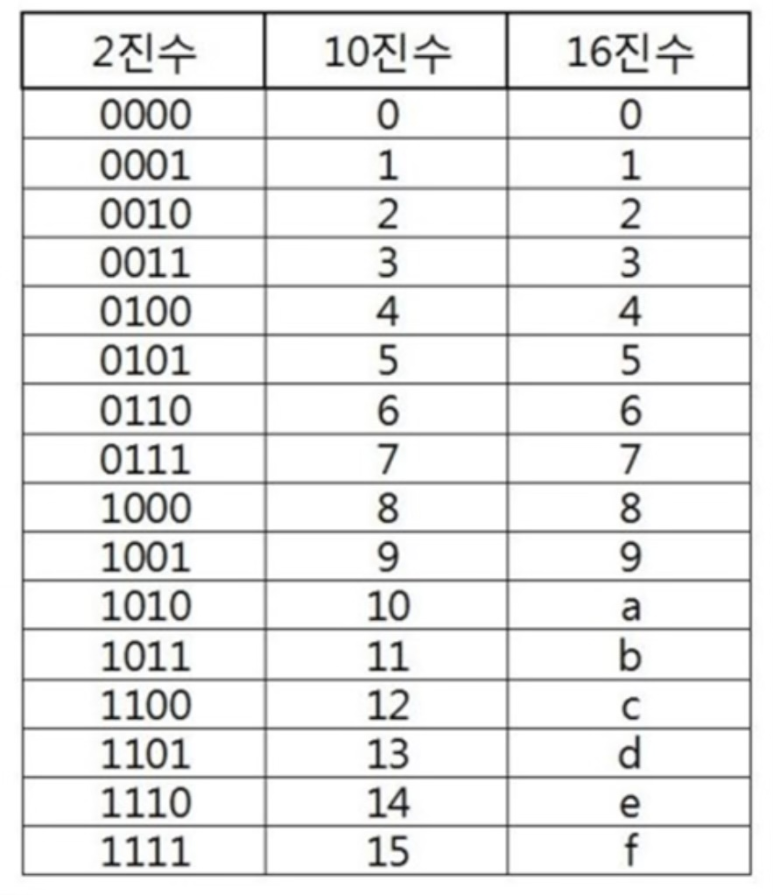
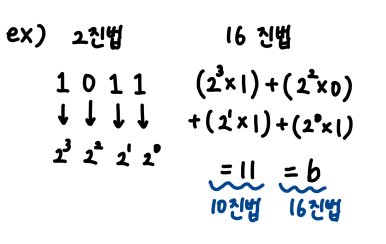
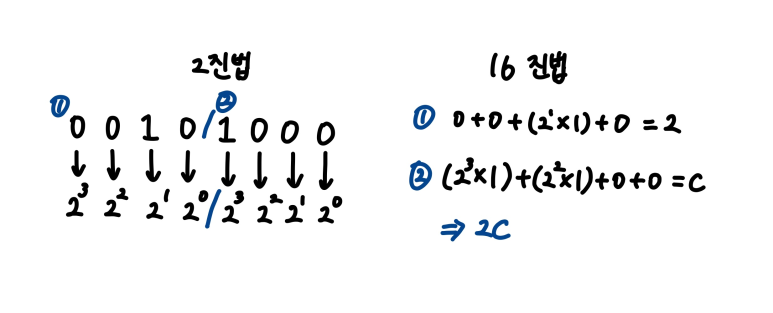
(진법 계산 예시)
<ASCII 코드>
: 미국정보교환표준부호 American Standard Code for Information Interchange 의 약자
: 영문 알파벳을 사용하는 대표적인 문자 인코딩 방법
: 총 128개의 문자로 이루어진다
* 파이썬으로 ASCII 코드 출력하는 방법
문자에 해당하는 숫자 조회 → ord('문자')
숫자에 해당하는 문자 조회 → chr(숫자)

<파이썬이란>
- 간결하고 읽기 쉬운 문법
- 객체지향 및 함수형 프로그래밍 지원
- 풍부한 라이브러리
- 인터프리터 언어 : 코드를 컴파일하지않고 바로 실행할 수 있다
→ 컴파일러: 전체 소스 코드를 읽어들여 기계어/중간코드로 번역한 뒤, 실행 가능한 파일로 저장
ex) C, C++, Java 등
→ 인터프리터: 소스 코드를 한줄씩 읽어들여 즉기 실행하여 실시간으로 코드 수정이 가능하다
ex) Python, Javascript, Ruby 등
* 프로그램 작성 순서
(주어진 문제를 먼저 해석하고 방법을 고민해볼 것!!!)
- 문제 이해
- 변수 고민
- 구조 고민
- 코딩
- 검증
CH01. 기본적인 사용법
<출력 방법>
- 함수를 사용하지 않고 원하는 값을 프롬프트에 넣고 실행시키면 입력한 마지막 줄의 값이 실행
print( )함수를 사용.
3. input( )함수를 사용. (추후 함수 부분에서 상세히 기술)
* 코드 셀에서 #을 입력하면 #오른쪽의 글들은 주석처리된다
* 긴 범위를 주석처리하고싶다면 ''' (범위) '''
<변수>
: 데이터를 저장하고 추후에 사용할 수 있게 해주는 저장공간
: 이름과 값으로 구성된다
: 변수의 이름은 참조할 때 사용되고, 변수의 값은 실제 데이터를 의미한다
: 같은 숫자들로 여러 연산을 하고싶을때 편리하다는 특징
: 변수 이름 = 저장할 값
: 헝가리식 표기법으로 변수 이름을 설정할 수 있다
ex) nNumber, StrName → 변수이름 앞에 n, str등 타입을 기입



***변수를 지정하더라도 이후에 새로운 값을 할당하여 값을 변경할 수 있음*** ***한줄에 여러개의 변수 값을 할당할 수 있고, 서로 다른 변수가 같은 값을 지정할 수도 있음***
: 변수를 삭제하고 싶다면, del 사용
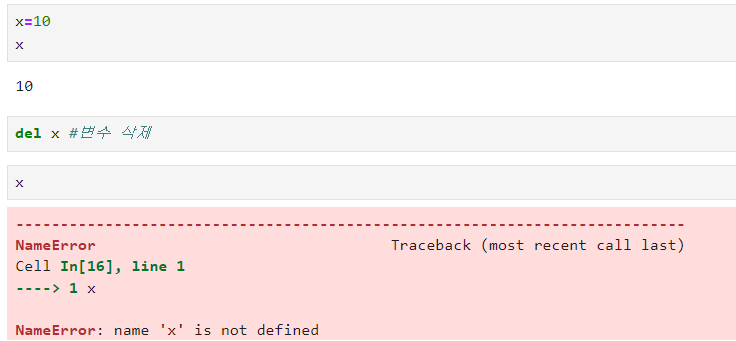
: 변수의 이름 = 변경할 값 → 기존에 존재하던 변수가 새로운 값으로 바뀐

* copy() 함수
: b = a 라고 변수끼리 연결했을 때, a 리스트의 요소를 바꾸면 b 도 함께 변화한다.
이때 둘은 리스트의 객체가 같이 때문에 저장된 아이디 공간이 같아 연결되는 것.
따라서 b가 a의 값을 가져오지만 저장된 아이디 공간을 다르게 해주기 위해서 copy함수 사용가능

* 이름 규칙
: 영문자(대/소문자 구분), 숫자, 언더바( _ ) 의 조합으로 이름을 만들 수 있다
: 단, 숫자가 맨 앞에 올 수는 없다
: 공백은 들어갈 수 없음
ex)
a_1, A_1, _kkampu --- (ok)
1a, @kkampu, kkam pu --- (error)
* 변수의 종류 (as 자료형)
- 숫자형
- 문자형
- 리스트 list, [ ]
- 튜플 tuple, ( )
- 딕셔너리 dict {key : value}
- 집합 set { }
※시퀀스(연속적) : 리스트, 튜플, range함수, 문자열과 같이 값이 연속적으로 이어진 자료형을 시퀀스 자료형이라고 부름
※시퀀스 객체 : 시퀀스 자료형으로 만든 객체 요소

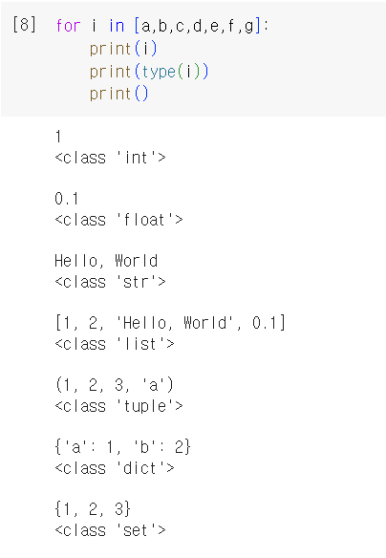
* 숫자형 데이터의 연산 종류
- 기본 사칙 연산 ( + - * / )
- 그 외 연산


3. 할당 연산
: 변수 x 에 이미 값이 부여되어있을때, 변수 x에 n을 더해서 x에 덮어씌우는 것


사칙 연산에 모두 적용 가능, 단 사칙연산 기호를 왼쪽에 등호를 오른쪽에 붙여줘야한다
* 문자열
: 문자 형태로 이루어진 자료형
: 큰 따옴표 " " 혹은 작은 따옴표 ' '로 감싸주면 문자열로 인식한다 (단, 한 문자열에 혼용하면 에러 발생)
: 문자열 안에 따옴표를 넣고 싶다면, 다음과 같은 방법으로 작성할 수 있다
" '(문자열)' " , ' " (문자열) " ' → 서로 다른 따옴표 사용하기
" \(문자열)\ " , ' \ (문자열) \ ' → \ 혹은 ₩ 기호로 문자열 감싸주기

: 여러 줄의 문자열을 하나의 변수에 넣으려면, 주석처리와 비슷하게 ''' 혹은 """ 로 여러 열을 감싸준다
혹은, 한 줄의 문자열 사이에 줄바꿈 기호 (\n)를 사용하여 여러줄로 출력할 수 있다

* 인덱싱
: 변수이름 뒤에 [ ]를 통해 인덱스를 설정할 수 있으며, 변수의 값에서 인덱스 번호에 해당하는 하나의 값을 추출할 수 있다
: 첫번째 위치는 0부터 시작. 맨 마지막 위치는 -1로도 표기할 수 있다
: 공백도 한 칸으로 인정됨
: 콜론( : )으로 슬라이싱을 할 수 있다 ex) 변수[ 시작인덱스 : 끝 인덱스 : 간격 ]
: 슬라이싱 간격을 작성하지않으면 1을 기본값으로 둠
: 시작 혹은 끝 인덱스를 공백으로 두면 각각 0번부터, -1까지로 간주한다

<print( )함수>
: 결과물을 출력하는 함수
: print(변수 or 출력하고 싶은 결과물/값)
: 여러 값을 한 줄에 출력할 수 있음
ex) [입력] print('a', 'b', 'd', 'e') → [출력] a b c d
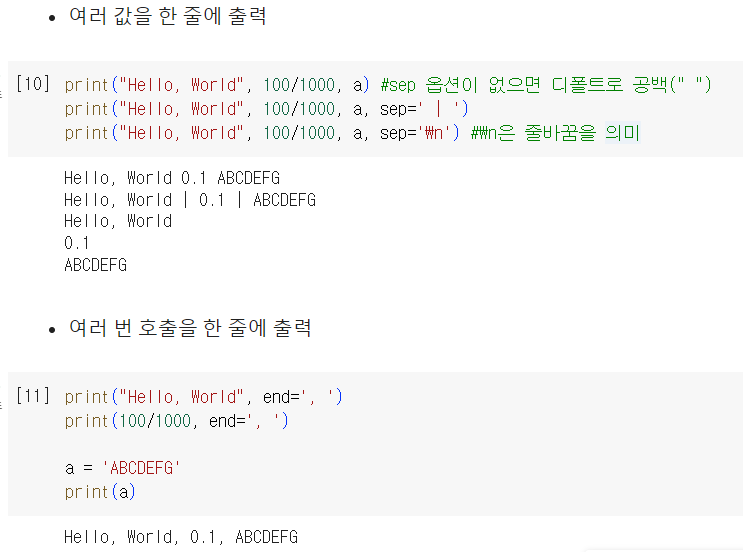
print(변수1, 변수2, ... , ? )
? 부분에는 디폴트로 sep = ' ' 이 입력되어 여러 개의 변수가 띄어쓰기 없이 출력된다
만약, ? 부분에 sep = ' (원하는 구분기호) '를 입력하면 여러 개의 변수가 구분기호로 분리되어 출력됨
sep='\n' 은 줄 바꿈, sep='\t' 는 탭키 명령어
혹은 여러 줄로 작성된 print 결과값을 한줄로 출력하고 싶다면
print(변수1, ?)
print(변수2, ?)
? 부분에 end=' (원하는 구분기호) ' 를 입력하면 구분기호에 따라 여러 개의 변수가 한 줄에 출력된다
<문자열 함수>
- len(a) : a라는 문자열 길이 출력
- int(a) , float(a) : a라는 문자열을 각각 정수, 실수형으로 바꿔줌
- a.upper() : a라는 문자열을 모두 대문자로 변환한 값 출력
- a.lower() : a라는 문자열을 모두 소문자로 변환한 값 출력
- a.lstrip() , a.rstrip() , a.strip() : a라는 문자열의 왼쪽, 오른쪽, 양쪽 공백을 제거하여 출력
- x.count('b') : x라는 문자열에 b라는 문자열이 몇개 포함되어있는지 세어줌
→ b는 변수이름이 아니므로 따옴표를 사용해 문자열 표시
- x.find('b') : x라는 문자열에 b라는 문자열이 몇번째 위치에서 처음 등장하는지 위치 인덱스 반환
→ 문자열이 없으면 -1을 반환 (FALSE와 같은 의미)
- x.index('b') : find와 비슷하지만 x라는 문자열에 b 문자열이 없으면 오류 발생
- " 구분기호 ".join('a') : a 문자열에 구분 기호를 사용해 각 문자마다 슬라이싱

- x.split( ' 구분기호 ' ) : 구분 기호를 기준으로 x라는 문자열을 나누기

- a.replace('x', 'y') : a변수 안의 x라는 문자열을 y로 변경

- a.startswith('x') , a.endswith('x') : a변수안의 문자열이 x로 시작하는지 혹은 끝나는지

- x = input('입력할 때 띄우고 싶은 말')
: x라는 변수에 넣고싶은 변수를 사용자가 직접 입력할 수 있고 화면에는 input 함수 안의 문자가 출력
: input으로 입력된 값은 기본적으로 str 타입이며 int( ) 등으로 감싸 데이터 타입을 변경할 수 있음

- format(x) : 문자열 안에 x라는 값을 삽입

여러개의 변수를 삽입할 수 있음
<리스트 List>
: 요소들의 모음을 나타내는 자료형
: 요소들을 대괄호 [ ]로 감싸주어 만들 수 있다
: 모든 자료형을 리스트의 요소로 담을 수 있다

: 리스트에 인덱스를 적용하여 값을 불러올 수 있다

: 더하기와 곱하기 연산이 가능하다

+ : 리스트와 리스트를 순서대로 연결 * : 리스트를 숫자만큼 반복 출력

*** 서로 다른 자료형끼리는 연산할 수 없다***
: 리스트는 인덱싱을 통해 값 수정/삭제 가능

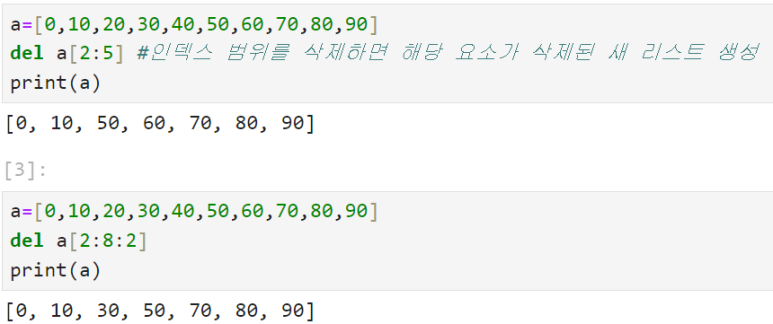
***단, 범주를 인덱싱하고 하나의 요소만으로 바꿀 수는 없음***
<리스트 함수>
- len()
- sum(), min(), max() : 리스트 요소들의 합, 최소값, 최대값을 구함
(단, 리스트의 요소가 숫자가 아니라면 에러 발생)
- in, not in : 특정 요소가 리스트 안에 있는지 확인

- append(), extend() : 리스트의 맨 마지막에 append는 요소를 추가, extend는 다른 리스트를 추가

- insert() : 리스트의 특정 위치에 특정 요소를 삽입 ex) ls.insert(인덱스번호, 삽입할 값)

- remove(), pop() : 리스트의 요소를 삭제
(remove는 특정 요소를 제거, pop은 특정 위치의 요소를 제거하여 그 요소를 반환)

- count() : 리스트의 특정 요소의 개수 반환
- index() : 리스트에 요소가 있는 경우 인덱스 값을 반환

cf) 리스트의 인덱스번호로 요소를 출력하는 것과 요소의 인덱스값을 반환하는 것은 차이가 있다
a[1] = 'b' → 리스트a의 인덱스 번호 1번에 해당하는 값인 'b'가 반환
a.index(1) = 2 → 리스트a에 1이 있다면 1의 인덱스 위치 번호를 반환
- sort, sorted : 리스트 정렬
(sort는 리스트를 정렬된 리스트로 바꾸지만, sorted는 정렬한 값을 보여줄 뿐 리스트 자체의 배열을 바꾸지않음)
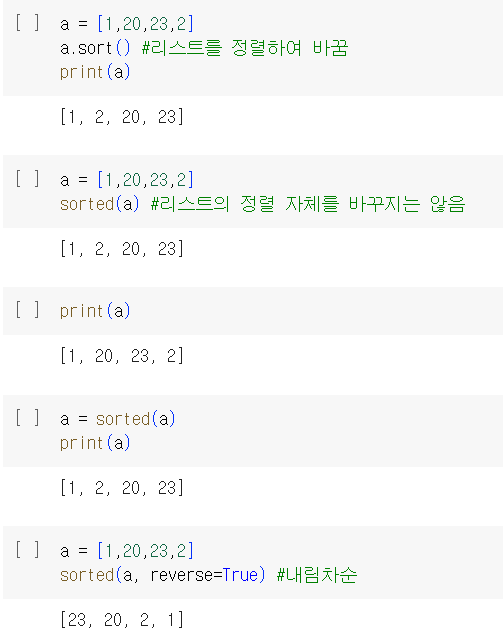
- join : 리스트의 요소들을 하나의 문자열로 합침 ex)'문자열'.join(리스트)

- split()
<range 함수>
: range(시작, 끝, 간격) → 시작부터 끝-1 범위의 값을 간격에 따라 출력해주는 함수
ex) range(10) = range(0, 10)
list(range(10)) = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
list(range(1, 10, 2)) = [1, 3, 5, 7, 9] → 1~10까지 범위안에 있는 홀수 리스트를 만들어줄 수 있다
llist(range(10, 0, -1)) = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
: range 자체로는 연산자 사용 불가능하므로 리스트나 튜플로 변경하여 사용한다
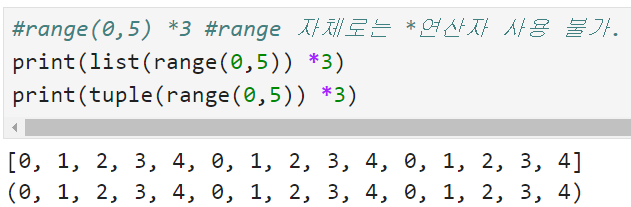
<튜플 tuple>
: 여러 요소들을 묶어 한 그룹으로 만들 수 있다
: 그러나 튜플은 읽기 전용이기 때문에 튜플의 요소는 수정이나 삭제가 불가능 (리스트는 수정/삭제 가능)
→프로그램 실행 중 변하지 않거나 고정해야하는 값을 튜플로 저장하는 것이 편리
: 요소들을 괄호 ( ) 로 감싸주면 튜플이 된다
: a = 1, 2, 3, 4, 5 와 같은 형식으로 작성하더라도 print(a) = (1, 2, 3, 4, 5) 튜플 형태로 저장


: 인덱싱을 적용해 값을 찾아볼 수 있다


: 더하기 곱하기 연산이 가능 (단, 다른 자료형과 더하기는 불가능)

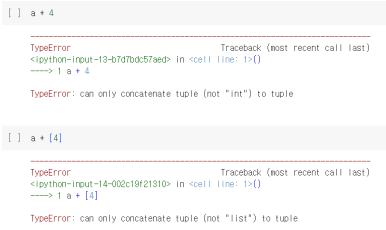

***튜플끼리는 더할 수 있다***
: sort()는 사용할 수 없지만 sorted()는 튜플을 리스트로 변환하여 요소를 정렬해서 반환해준다

<튜플 함수>
- len()
- sum(), min(), max()
- in, not in
- count()
- index()
- join()

***그러나 insert, pop 등 튜플 자체를 변경하는 함수는 사용할 수 없다***
max( 튜플 이름, key = lambda x:x[인덱스] ) or min( 튜플 이름, key = lambda x:x[인덱스] )
: 다중 튜플의 경우 정렬 기준을 정의하여 튜플 내 최대/최소값을 탐색

<딕셔너리 dictionary>
: {키 key : 값 value} 의 쌍이 모여있는 사전 형태의 자료형
: 중괄호 { } 로 감싸주어 표현
: 키는 중복될 수 없고, 리스트는 키가 될 수 없음 (값은 리스트 가능)
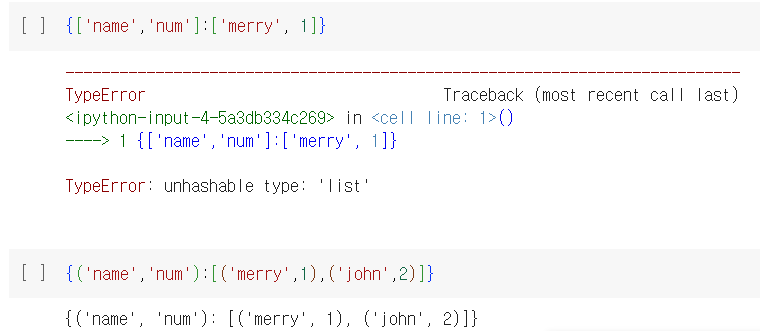
: 위치가 없기 때문에 인덱싱 불가능
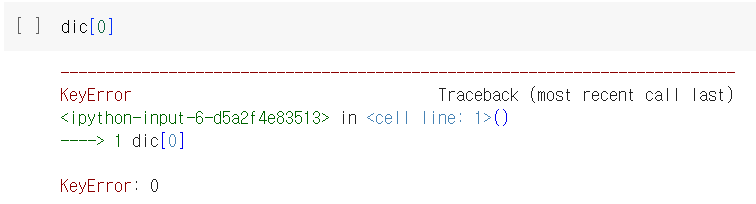
: 딕셔너리 키로 값을 찾을 수 있다

: 인덱스를 사용하고 싶다면 딕셔너리를 리스트로 감싸 리스트로 형식을 변경해준뒤 인덱싱 가능
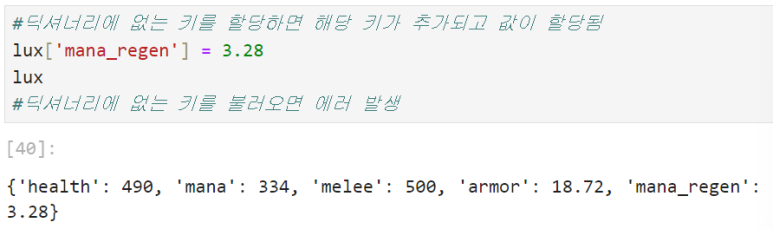
: dic_a[key_name] = 추가할 값 → dic_a에 키와 값을 추가할 수 있다
del dic_a[key_name] → dic_a에 키를 삭제하여 딕셔너리를 수정할 수 있다

<딕셔너리 함수>
- keys() : 키들을 반환
- values() : 값들을 반환
- items() : 키와 값의 튜플 쌍들을 반환

- get(key_name) : 원하는 키 값에 대응되는 값을 반환 (dic[key_name]과 같은 값을 반환)

- update() : 딕셔너리에 새로운 딕셔너리를 추가하여 하나의 딕셔너리를 만들어준다

*but 딕셔너리에 없는 키 하나를 추가할 경우, 딕셔너리명[추가할 키] = 추가할 값을 입력하면 된다
- zip : 튜플/리스트 두개를 하나의 딕셔너리로 변환
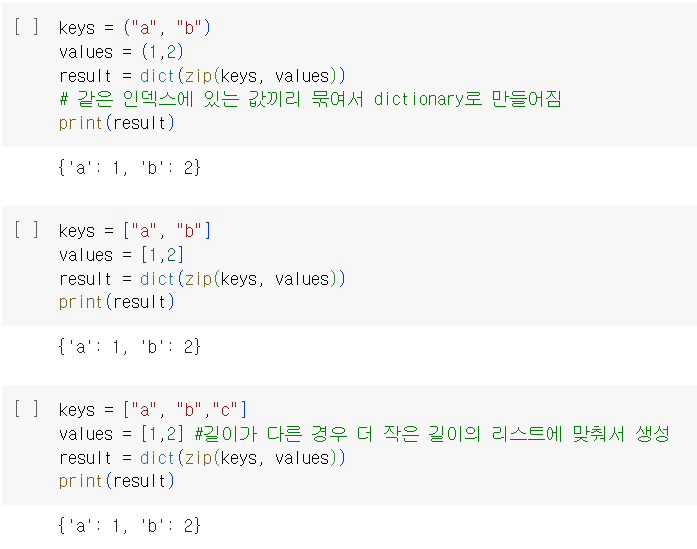
*딕셔너리 만드는 방법 4가지 정리

1. 중괄호 사용 2. zip 리스트 대응시키기 3. 튜플로 키:값을 묶어 리스트로 대응시키기 4.dict로 한번에 키:값 대응시키기

<집합>
: 순서가 없고 중복이 없는 자료형
: 요소들을 중괄호 { } 로 감싸주어 표현
: 문자열, 숫자, 리스트, 튜플을 요소로 가질 수 있음

: 순서가 없기때문에 인덱싱 X

<집합 함수>
- & , intersection : 교집합
- - , difference : 차집합
- | , union : 합집합

- add(), remove() : 요소를 추가 / 삭제

<불리언 boolean>
: 참 또는 거짓을 나타내는 자료형
: True or False로 나타내야한다
: 논리 연산자와 함께 사용



* 단락평가
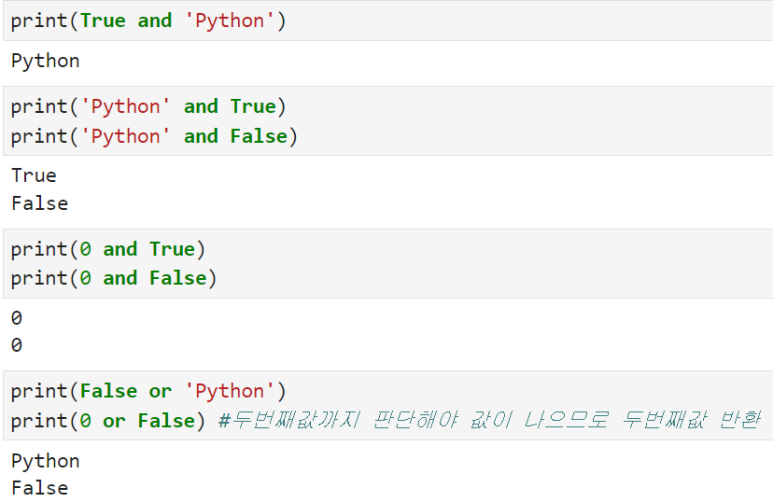
: 위와 같이 and/or 연산자로 연결되어있을 때, True 혹은 False가 결정되는 쪽에서 단락평가가 일어난다
ex) True and 'Python'
→ 첫번째 값은 True 이고 and로 연결되어 있으므로 두번째 값인 'Pyhton'에서 단력평가가 일어나므로 두번째 값 반환
ex) False or 'Python'
→ 첫번째 값이 False이고 or로 연결되어있어 하나라도 False이면 False를 반환하니까 첫번재 값 T/F 결정
ex) 0 or False
→ 첫번째 값이 True이므로 두번째 값에서 단락 평가가 일어난다
'DATA | IT > 패스트캠퍼스 BDA 13기' 카테고리의 다른 글
| [패스트캠퍼스 데이터 분석 부트캠프] 7주차_SQL 기초 문법 (0) | 2024.04.08 |
|---|---|
| [패스트캠퍼스 데이터 분석 부트캠프] 4주차_파이썬 제어문과 반복문(If문, While문, For문) (0) | 2024.04.08 |
| [패스트캠퍼스 데이터 분석 부트캠프] 2주차_기초 통계를 통한 데이터 탐색 (0) | 2024.04.08 |
| [패스트캠퍼스 데이터 분석 부트캠프] 1주차_엑셀 데이터 분석 기초 (0) | 2024.04.08 |
| [패스트캠퍼스 데이터 분석 부트캠프] 1주차_OT (0) | 2024.04.08 |



